
Advanced Deep Reinforcement Learning System for Trade Execution - Part V: Target DQN and Double DQN (Python)
Advanced Deep Reinforcement Learning System for Trade Execution - Part V: Target DQN and Double DQN (Python)


Photo by Steve Johnson on Unsplash.com
In one of my last posts in this series we implemented the Deep Q-Learning variant of the Deep Reinforcement Learning (DRL) for trading. In this part of the series, we are going to implement the Target DQN and Double DQN variants.
Suggested Reads:
Advanced Deep Reinforcement Learning System for Trade Execution: Part I: Foundation Concepts
Advanced Deep Reinforcement Learning System for Trade Execution: Part II: Feature Engineering
Advanced Deep Reinforcement Learning System for Trade Execution: Part III: DQN Implementation
This story is solely for general information purposes, and should not be relied upon for trading recommendations or financial advice. Source code and information is provided for educational purposes only, and should not be relied upon to make an investment decision. Please review my full cautionary guidance before continuing.
What is a Target Deep Q Network (t-DQN)?
In the DQN implementation in my last post a single network was used both to calculate target Q-values and to evaluate actions, which can lead to high variance in the updates and potentially unstable learning. The Target Q Network architecture helps to address this issue by adding a second neural network.
The Target Q network is a has the same architecture as the primary Q network but with its weights frozen for a certain number of steps. Its role is to provide a stable target for the Q-value updates. While the primary Q network is updated at every step or episode, the target Q network's weights are updated less frequently (e.g., every n steps) by copying the weights from the primary Q network.
This delayed update introduces a level of stability in the learning updates, preventing the target values from shifting too rapidly and thus allowing for more stable and reliable learning.
The Target Q network separately predicts the Q-value of the next state for all possible actions. The maximum Q-value from this prediction is taken to calculate the target-value for the action taken in the current state.
This calculation is implemented in this tutorial using the Bellman equation.
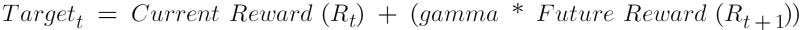
The gamma value is the discounting factor for the future reward.
The updated target function is then then used to train the primary DQN model.
t-DQN architecture:

Environment
Simulates trading by providing financial data, interfacing with a brokerage account, and tracking time, state, funds, and shares.
Q-Network
Approximates the Q-value function using deep learning to output potential action rewards from given state inputs.
Target Q-Network (t-DQN)
A secondary, periodically updated Q-Network that provides stable target values for the primary Q-Network's updates.
State Representation
Consists of market data and account details, serving as input for the Q-Network to evaluate action consequences.
Experience Replay
A memory buffer storing past state-action-reward sequences, enabling learning from historical data.
Epsilon Greedy Policy
Balances exploration and exploitation by selecting actions either randomly or based on Q-values, influenced by the epsilon parameter.
DQN Agent
Manages the iterative process of action selection, memory storage, environment interaction, and Q-Network training.
Take the emotions out of trading and free up hours of screen time by letting the algorithms do the work for you. Join Algohive and get an exclusive 50% discount on our membership.