
Is Peer Mutual Information the Ultimate ML Feature? (Python) ℹ️ℹ️ℹ️
Is Peer Mutual Information the Ultimate ML Feature? (Python) ℹ️ℹ️ℹ️

Data sourced with Yahoo Finance
In a recent post I wrote about ‘Tandem Stocks’ so stock pairs that are have a high degree of correlation, which means that there is a linear relationship between the stock prices of the pairs.
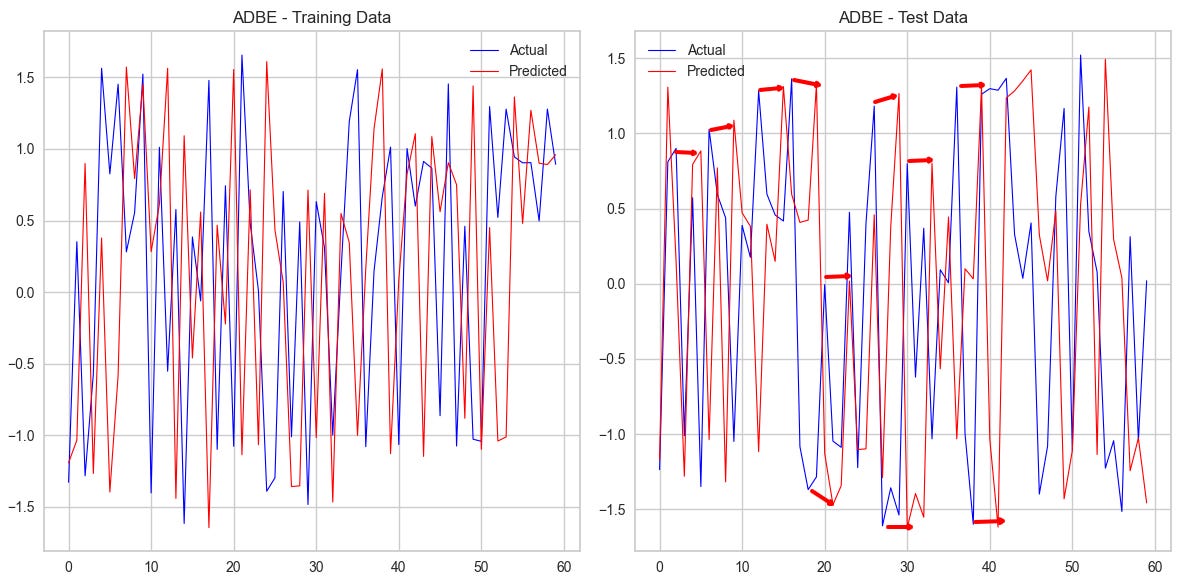
What if we didn’t use correlation but mutual information which also considers non-linear relationships as a feature between peer stocks for the analysis? Furthermore, what if we used multiple stock relationships and not only pair relationships as features? So we are basically examining the predictive capabilities of peer stock prices for the price of a particular stock.⚙️⚙️⚙️💡
Here my hypothesis: If we use stocks with the highest degree of mutual information in respect to a target stock as features in a Machine Learning (ML) model, we can predict the next period’s prices of some stocks with a degree of certainty.
That’s the hypothesis I want to test and that’s what this post is about. Sounds mildly intriguing? All right, then let’s get started!
Suggested Reads:
This story is solely for general information purposes, and should not be relied upon for trading recommendations or financial advice. Source code and information is provided for educational purposes only, and should not be relied upon to make an investment decision. Please review my full cautionary guidance before continuing.
What is Mutual Information? ℹ️
Mutual Information (MI) is a measure of dependence used in probability and information theory. According to Wikipedia, Mutual Information (MI) “quantifies the amount of information obtained about one random variable by observing the other random variable.”
To understand the concept of MI, let’s imagine the following scenario: There are two people, Bob and Alice. Alice is in a room without windows and is supposed to forecast whether it is going to rain today. Bob is outside and provides Alice with information to assist her weather forecast. Bob provides two pieces of information:
It is warm.
Is it very cloudy.
Based on these two pieces of information, which one do you think has more information to predict it will rain? The second one, right? That’s because the second information has a higher shared probability with the target outcome and thus the Mutual Information is higher.
The way the MI is calculated in practice is using the probability distributions of the variables involved. It involves complex calculations that look at how the actual distribution of one variable compares to what would be expected if it was completely independent of the other variable. A deep dive into the mathematical calculations would extend past the scope of this post but if you are curious, check out this Wikipedia page.
In previous posts we have already discussed the concept of “correlation”. Pearson correlation, for example, measures the strength and direction of the linear relationship between two continuous variables. MI on the other hand is nonparametric, which means it makes no assumption about the distribution and relation between the two variables. This means, an advantage of using MI is that it can find relationships between variables that are non linear in nature.